In this post, I want to highlight the new IT User Support Project site recently launched by AeRO (Australian eResearch Organisations). In particular there are some good resources that provide a plain English overview of tiered support services, which may be an unfamiliar concept to some librarians working in research support.
My place of work, like many other universities, has a converged model for delivering library and information technology services. This has a lot of benefits for librarians with a hybrid skillset, a desire to work in multidisciplinary teams, and an interest in areas such as research data management where collaboration across organisational boundaries is essential. There are also challenges, of course, including coming to grips with terminology and ways of working that are not what you may be used to (and that probably didn't get a mention in library school!).
Many IT services are now developed and managed in line with the Information Technology Infrastructure Library (ITIL), "a set of practices for IT service management (ITSM) that focuses on aligning IT services with the needs of business." As someone not previously exposed to ITIL, I am finding this approach to service development can take a bit of getting used to. It is worth trying to get your head around some of the basics though, as it is really relevant to academic libraries as well as IT. If you are interested in finding out more, I highly recommend a 2007 Red Dirt Librarian blog post by Carolyn MacDonald (Associate Director of Library and Learning Services at Griffith University) as a starting point.
One widely adopted idea from ITIL and similar service development frameworks is that of multi-tiered support. If you have heard people in your organisation talk about Tier 0, Tier 1, Tier 2 and Tier 3 support and wondered what on earth they meant, then head on over to the new AeRO support site. On the FAQs page, the section "What is Tier 0, 1, 2 & 3 support?" provides a plain English description of the different tiers, with examples. The focus is technical rather than on library services but you'll get the gist behind the multi-tiered model, which is to effectively use self-help materials and service desks to meet simpler needs while highly skilled staff only spend time on more complex activities.
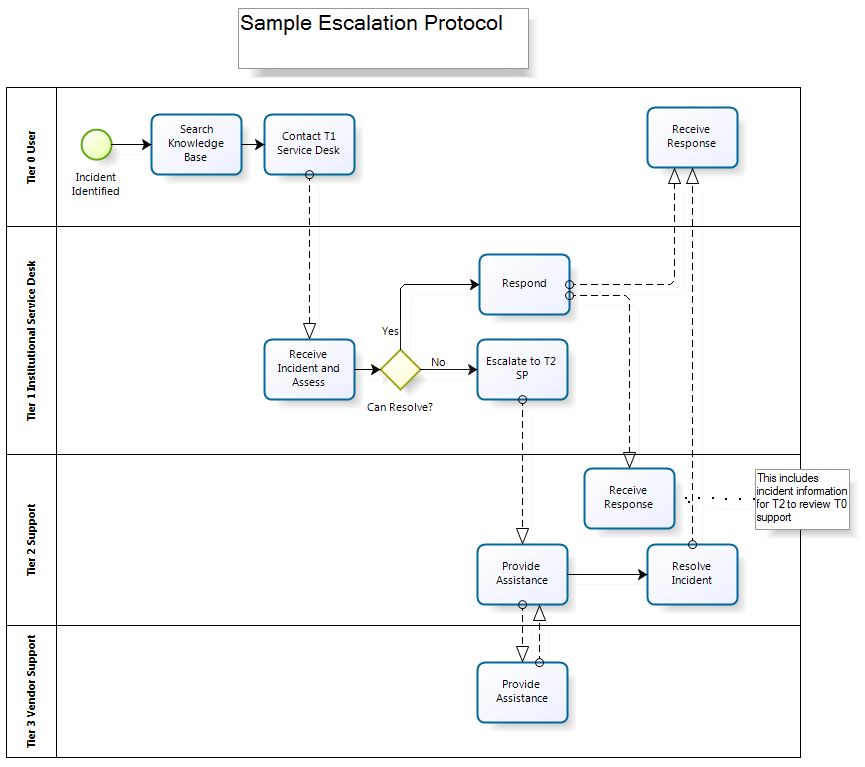
Within a larger suite of Good Practice Guides (all of which are worth a look), I found Tier 0 Materials and Escalation of Support Incidents most relevant to my current work on a support model and self-help materials for a new private cloud storage service for research data. The Tier 0 guide provides advice about how to create effective FAQs and user manuals, while the guide to escalating service incidents includes a great diagram showing a draft protocol for moving support requests through the different tiers. Importantly, this diagram shows how Tier 0 self-help materials should be updated continuously, as patterns are identified and solutions are documented during the resolution of higher tier requests.
If I have one criticism of this new site it is that AeRO has chosen to retain all rights over the content rather than apply an open licence. I hope AeRO might revisit this decision in future so that these useful resources can find a wider audience outside those directly involved in technical support.



{kind=link}